
バイトオーダー
ここでは「バイトオーダー」について説明します。
バイトオーダーというのは、「複数のバイトからなるデータ」があったときに、そのバイトを並べる順番のことです。
「バイト」というのは、歴史的には必ずしも 8 ビットではありませんが、 現在は IEC 80000-13 で 1 バイトは 8 ビットと定義されています。
「複数のバイトからできているデータ」というのは、例えば「int 型が 4 バイトで 1 つの整数を表す」とか「ワイドキャラクタは 2 バイトで 1 文字表す」というような場合です。
C 言語の char 型などは、もともと 1 データ 1 バイトでの表現なので、バイトオーダーという考えはありません。
バイトオーダーの例
例えば、"ABC" という文字列を考えてみましょう。
"ABC" という文字が ASCII コードで記述されている場合、ASCII コードの 1 文字 1 文字は 1 バイトで表せて A = 0x41、B = 0x42、C = 0x43 なので、 ABC はバイト列としては 414242 になります。
この場合、1 データ 1 バイトなので、バイトオーダーというのは考えはありません。ただ、文字コードを並べていけば OK です。
次に文字コードとして UCS-2 を考えてみます。
UCS-2 は 2 バイトの文字コードで Unicode の BMP 部分です。2 バイトで構成される「元祖 Unicode」位に考えておいてください。文字コードのことまではなし始めると、余計に複雑になるので、ここではざっくり考えておいてください。ASCII コードにしても「 1 バイトっていうか 7 ビットじゃん」とか言い出すとキリがないので・・・。
同じ "ABC" でも、UCS-2 では 1 文字毎に 2 バイトで表現します。UCS-2 のコード表をみると、次のように記載があります。
... [A] 0041 LATIN CAPITAL LETTER A [B] 0042 LATIN CAPITAL LETTER B [C] 0043 LATIN CAPITAL LETTER C ...
それなら、UCS-2 で "ABC" と書いたら、そのデータを構成するバイト列は 0041 0042 0043 となるのでしょうか? 実際に確認してみましょう。
次のコマンドで、 UCS-2 で "ABC" と書いたときに出来上がるバイト列をみてみましょう。
echo ABC | tr -d '\n' | iconv -f ASCII -t UCS-2 | xxd
00000000: 4100 4200 4300 A.B.C.おや? 0041 ではなく 4100 というのが見えてますね。これはどういうことでしょうか?
コマンドに慣れていない人は、ごちゃっとして見えると思いますが、とりあえずここでは文字コードを見たい、というだけです。テキストファイルをバイナリエディタで開くとか、そういうのでも構いません。
ちなみに上のコマンドは Linux で使えます。一応説明すると、iconv コマンドは -f オプションで指定した文字コードから、 -t オプションで指定した文字コードに変換して、結果を標準出力に出力します。iconv コマンドへの入力して、 echo コマンドで ABC という文字を標準出力に出力し、 tr コマンドの -d オプションで改行文字 \n を削除してから、 iconv コマンドに送っています。 iconv コマンドの結果は、xxd コマンドに送って、16 進数で表示している、ということになります。
さらに、次のように "UCS-2BE" という文字コードを指定すると、今度は 0041 が出てきました。
echo ABC | tr -d '\n' | iconv -f ASCII -t UCS-2BE | xxd
00000000: 0041 0042 0043 .A.B.C0041 を 4100 とするか、0041 とするか、 この違いがバイトオーダーの違いです。
リトルエンディアンとビッグエンディアン
先の例で 0041 というデータを 4100 としたように、下位のバイトを先に書く方法を「リトルエンディアン」といいます。この場合、バイト列を目で見たときには逆さまになります。
一方、0041 のように上位のバイトを先に書く方法を「ビッグエンディアン」といいます。この場合、普通に文字を読む順番と同じになります。
ハードウェアによって使うバイトオーダーも変わる
普通のデスクトップ PC では、メモリにデータをロードするときやそれをプロセッサで処理する時にはリトルエンディアンを使います。
普通のデスクトップ PC とは Intel x86/x86-64 (AMD64) とか 2006 年以降のインテルアーキテクチャの MAC OS を指してます。
つまり、メモリ上に複数バイトからなるデータをロードするときには、下位バイトを先にロードします。「先に」というのは、若いアドレスにロードするということです。
一方、インターネットなどの TCP/IP ネットワーク上では、バイトオーダーはビッグエンディアンとすることになってます。 ネットワークバイトオーダーといえばビッグエンディアンのことです。
ネットワーク上にはいろいろなハードウェアが接続されているので、ネットワーク上のバイトオーダーを取り決めておき、 データを受け取ったそれぞれのコンピュータが適宜意味を解釈して適切に処理するわけです。
デバッガでメモリを見る例
前述の通り通常の PC 内ではメモリ上のデータは、リトルエンディアンで格納されています。 デバッガなどで生データをみるときはバイトオーダーに注意が必要です。
例えば次のようなコードがあって、int 型は 4 バイトで変数 i がアドレス 0x7fffffffdb44 からロードされていることがわかったとします。 かつ、プログラム上で i = 12345678 (16 進数で 00BC614E) をセットしてあります。
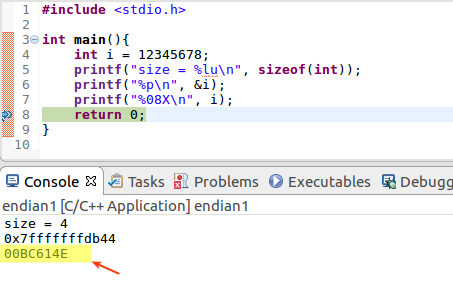
int 型が 4 バイトなので、アドレス 0x7fffffffdb44 から 0x7fffffffdb47 までの 4 バイトを使いますが、 リトルエンディアンなので、アドレスの若い 0x7fffffffdb44 から順番に、 4E、61、BC、00 がロードされています。
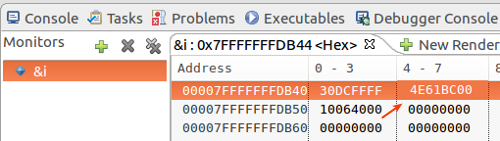
リトルエンディアンなので、 00BC614E というままの形では見えてこないで、人間が読む並びとは逆さまになっていますので注意しましょう。
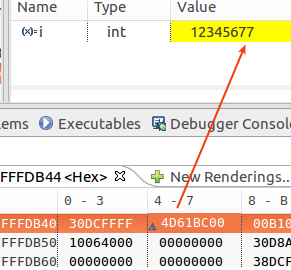
試しに 0x7fffffffdb44 の値を 4E から一つ減らして、 4D にすれば、確かに対応する i の値は 12345677 に変わりました。
テキストファイルなどのデータファイルは?
テキストファイルなどでも、1 文字複数バイトで表現するときなどは、もちろんバイトオーダーはかかわります。
データフォーマットがあらかじめ決めてあれば 「これはナントカ形式のデータファイル」とわかれば、 フォーマットの定義としてバイトオーダーがわかる場合もあります。あるいは自明ではない場合は、バイトオーダーマーク (BOM) といって、 バイトオーダーを宣言するためのマーカーデータをコッソリ埋め込む場合もあります。
例えば UTF-16 ではリトルエンディアンで記述する時は先頭 2 バイトを FFFE とし、 ビッグエンディアンの時は FEFF という BOM を埋め込んだりします。
cat a.txt | xxd
00000000: fffe 4100 4200 4300 0a00 ..A.B.C...この場合 BOM は必須ではなくて、Windows のメモ帳では常に BOM を埋め込み、Ubuntu の gedit などではリトルエンディアンでの保存時のみ BOM を付けています。
ちなみに UTF-8 では EF BB BF ということになってますが、これは必須でもなければ推奨もされていません。バイトストリームとして、 頭からどんどん読み下すので UTF-8 エンコーディングではバイトオーダーの意味はありません。